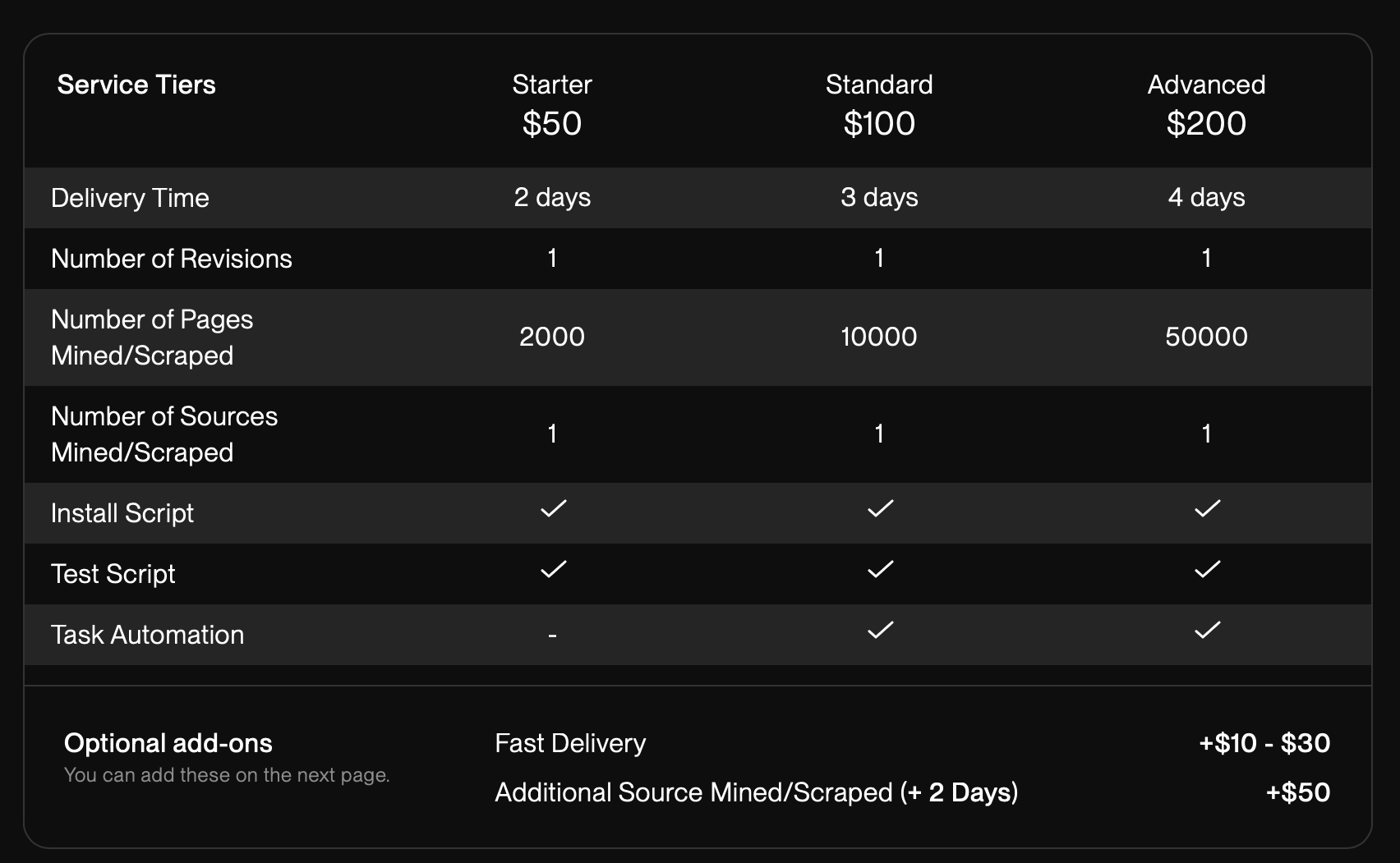
Web Scraping Service


You will get a website scraping script in python
Looking to extract valuable data from websites but facing challenges with anti-bot measures, CAPTCHAs, or complex structures?
Look no further! I specialize in creating custom Python scripts to scrape websites and deliver the data you need, in the format you prefer.

What I Offer:
FAQs
Can you scrape websites with anti-bot protection or CAPTCHA?
Yes, I use advanced techniques to bypass anti-bot protections and solve CAPTCHAs where possible. This includes using rotating proxies, user-agent switching, and CAPTCHA-solving services to ensure smooth and uninterrupted data extraction.
What types of websites can you scrape?
I can scrape a wide range of websites, including e-commerce platforms, directories, job portals, and more. If the website has the data you need, I can develop a script to extract it, provided it complies with ethical and legal standards.
What data formats can you provide?
I can deliver the extracted data in various formats, including CSV, Excel, Google Sheets, or directly into a database of your choice. You can specify your preferred format, and I'll ensure the data is organized and ready for use.
How long does it take to complete a scraping project?
The time required depends on the complexity of the website and the volume of data to be extracted. For simple websites, it may take a few hours to a day. More complex sites with anti-bot measures or large datasets may take longer. I will provide an estimated timeline after reviewing your requirements.
How do you handle websites that require login or have dynamic content?
For websites requiring login, I can integrate authentication into the scraping script. For dynamic content, I use tools like Selenium or Puppeteer to render JavaScript and extract the necessary data.